数字人开源项目( github star 排序 2024-10-31 )
git clone https://github.com/xszyou/Fay
git clone https://github.com/Zejun-Yang/AniPortrait
git clone https://github.com/lipku/LiveTalking
git clone https://github.com/BadToBest/EchoMimic
git clone https://github.com/TMElyralab/MuseV
git clone https://github.com/Kedreamix/Linly-Talker
git clone https://github.com/ZiqiaoPeng/SyncTalk
git clone https://github.com/MyNiuuu/MOFA-Video
git clone https://github.com/anliyuan/Ultralight-Digital-Human核心逻辑
- 语音转文本 (文本输入)
- llm 实时文本生成
- 文本转语音
- 3D数字人视频生成( 实时 / 任务型 )
全能数字人框架功能
- 换脸直播实时生成数据流
- 换脸视频
- 图片生成视频
- 根据描述生成视频
数字人业务
- 数字人分身
- 智能交互
功能效果区分
| 功能 | 过程 |
|---|---|
| 虚拟人3D人直播 | 文本生成视频(3D) |
| 描述生成视频 | 文本生成视频(auto) |
| 图片生成视频 | 图片生成视频 |
| 交互式数字人 | 语音得到回应数字人 |
| 换脸视频 | 视频生成视频 |
模型
- Ernerf:多模态预训练模型,适用于图像生成、文本生成等任务。
- MuseTalk:音乐生成模型,能够生成高质量的音乐作品。
- Wav2Lip:唇形同步生成模型,用于将音频转换为唇形动画。
- Gradio 是一个开源库,用于快速创建和共享机器学习模型的交互式界面。它允许开发者只需几行代码就能将模型包装成一个用户友好的Web应用程序,非常适合原型设计、演示和部署。
- FunASR 是一个开源的语音识别工具,能够识别和理解自然语言。
- GPT-SoVITS / edge-tts 是一个开源的文本到语音合成工具,能够将文本转换为语音。
- Talking Head Generation 是一个开源的数字人模型,能够生成逼真的数字人视频。 MuseTalk
交互式数字人
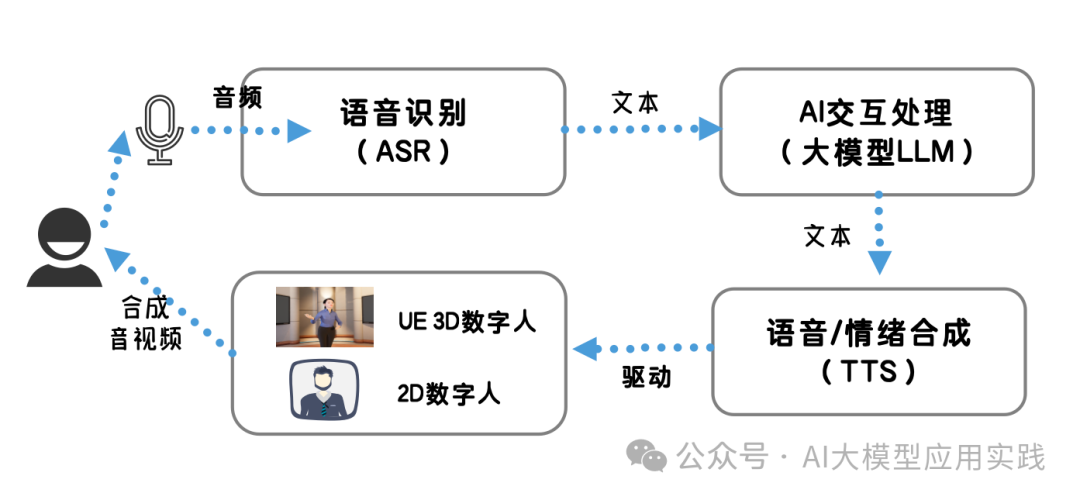
数字人制作流程

案例
https://business.xiaoice.com/Home/AIBeing
数字人将会接管80%网络服务行业!